
 6 comments
6 comments Business Intelligence
Business Intelligence 
Achtergrond
In de gesprekken, discussies en uitleg over diverse SQL-, NoSQL- en/of Big Data systemen wordt vaak het CAP-theorema aangehaald. Het CAP-theorema, opgesteld in 2000 door Eric Brewer, gaat over computersystemen in de breedste zin van het woord en stelt dat een willekeurig gedistribueerd systeem maximaal twee van de drie gewenste eigenschappen op het hoogste niveau kan garanderen met betrekking tot de data in het systeem:
- Consistency
- Availability
- Partition Tolerance
Het CAP-theorema is bewezen in 2002, en daarom wordt er graag naar verwezen in artikelen, lezingen en cursussen. Echter, hoewel het theorema bij een eerste lezing zeer intuïtief aanvoelt, zijn bij het opstellen ervan niet de meest duidelijke termen gebruikt, en is het bewijs ook een stuk strikter dan de oorspronkelijke stelling. In diverse artikelen en presentaties bestaat er daarom nogal eens verwarring over waar systemen te plaatsen zijn en waarom. Het verkeerd plaatsen en/of interpreteren van het CAP-theorema en de conclusies daaruit leiden daarmee tot een verkeerd informeren van gebruikers.
In deze weblog wil ik in vijf punten duidelijk maken wat belangrijk is om te weten over het CAP-theorema:
- Waarom er verwarring over de betekenis van het CAP-theorema bestaat
- Wat de termen ‘Consistency’, ‘Availability’ en ‘Partition Tolerance’ betekenen
- Waarom de werkelijke keuze pas begint bij het optreden van partities
- Waarom sommige standaard-voorbeelden van CAP niet standaard-correct zijn
- Waarom een goede voorkennis onmisbaar is bij het plannen van een gedistribueerd systeem
Waarom er verwarring over de betekenis van het CAP-theorema bestaat
Het CAP-theorema gebruikt drie termen die intuïtief eenvoudig begrepen worden: Consistency, Availability en Partition Tolerance. Deze termen – hoewel bekend – hebben echter een strikte uitleg in de scope van dit theorema. De verwarring over het CAP-theorema treedt daarmee letterlijk bij alle letters op:
- Bij ‘Consistency’ is de eerste associatie vaak transactional consistency, zoals deze bedoelt wordt in het acroniem ‘ACID’.
- Bij ‘Availability’ is de eerste link gedachte ‘High Availability’ of database-availability-technieken als mirroring, (hot/cold) standby systems etc.
- ‘Partition Tolerance’ wordt ten slotte vaak geassocieerd met horizontale schaalbaarheid: in hoeverre is een systeem te verdelen over meer nodes?
De associaties die hierboven genoemd zijn, zijn erg logisch. Ze zijn echter niet de termen zoals Eric Brewer en consorten ze bedoeld hebben, en hebben dan ook geen relatie met het bewezen CAP-theorema.
Wat de termen ‘Consistency’, ‘Availability’ en ‘Partition Tolerance’ betekenen
Het CAP-theorema stelt dat een willekeurig gedistribueerd systeem maximaal twee van de drie gewenste eigenschappen ‘Consistency’, ‘Availability’ en ‘Partition Tolerance’ op het hoogste niveau kan garanderen met betrekking tot de data. De betekenis van de drie termen is als volgt:
- Consistency gaat erover dat overal in het systeem dezelfde state aanwezig is. Alle clients hebben altijd dezelfde ‘view’ van de data.
- Availability gaat over het kunnen uitvoeren van updates. Voorwaarde hiervoor is wel dat het systeem überhaupt bestaat. Availability gaat dus (in het CAP-theorem) niet over het al of niet bereikbaar zijn van systemen! Brewer zegt hierover: “If users cannot reach the service at all, there is no choice between C and A except when part of the service runs on the client.” 2
- Partition tolerance gaat ten slotte over de vraag of een gedistribueerd systeem, als het door wegvallende communicatie tussen n delen opgebroken wordt, ook in n losse delen blijft functioneren. Een ‘partitie’ is hiermee dus een deel dat qua verbinding los staat van de rest van het systeem. Partition Tolerance gaat dus niet direct over schaalbaarheid.
Waarom de werkelijke keuze voor CAP pas begint bij het optreden van partities
In het CAP-theorema gaat het bij ‘partities’ niet over het bewust in delen opbreken van het systeem, maar over het ontstaan van partities in een gedistribueerd systeem. Partities ontstaan wanneer een gedistribueerd systeem in meerdere delen ‘uiteenvalt’ die (tijdelijk) niet met elkaar kunnen communiceren.
Stel dat we een gedistribueerd systeem hebben bestaand uit een server in Amsterdam, en één in Dublin. Zolang het netwerk goed werkt, is het eenvoudig om hier zowel Availability als Consistency te garanderen: Een gebruiker doet een update in Amsterdam (1), deze wordt vervolgens ook doorgevoerd in Dublin (2), en de staat blijft consistent:
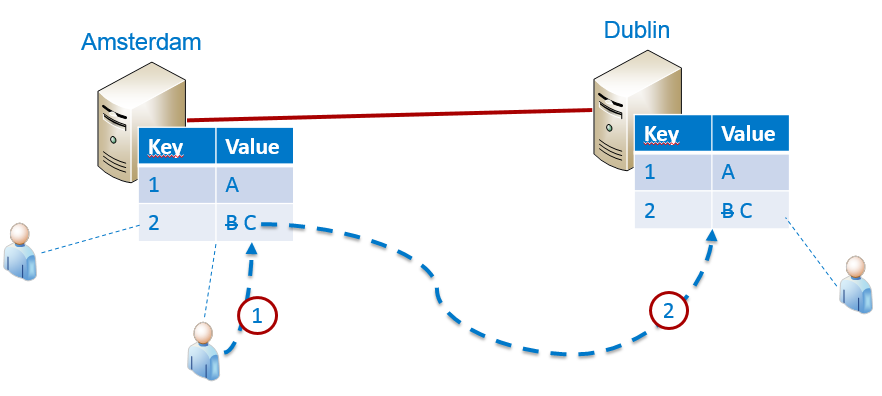
Zolang de verbinding in stand blijft, is er geen probleem: zowel C als A kunnen gegarandeerd worden. Wanneer de verbinding echter wegvalt, ontstaan er twee partities: één in Amsterdam, en één in Dublin. De vraag is nu hoe het systeem verder blijft functioneren.
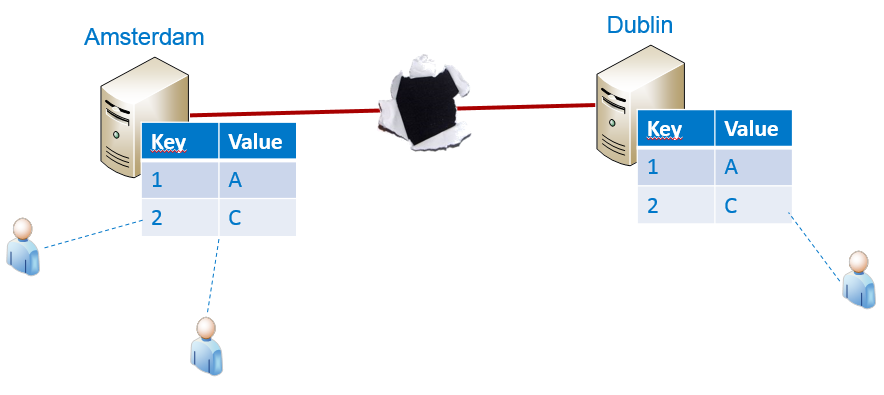
Op dit moment moet een keuze gemaakt worden welke van de drie factoren we niet meer kunnen garanderen:
- Wanneer we Partition Tolerance opgeven blijft hoogstens één partitie van het systeem in werking bij een verbroken verbinding – bijvoorbeeld Amsterdam blijft in werking, Dublin wordt uitgeschakeld. Op de Amsterdam-server kan iedereen echter blijven lezen en schrijven, en de data over het systeem als geheel wordt niet inconsistent. Availability en Consistency blijven dus in dit geval gewaarborgd.
- Wanneer we Availability opgeven blijven beide partities beschikbaar, maar mogen er geen updates doorgevoerd worden. Beide partities blijven onafhankelijk van elkaar functioneren en de consistentie blijft gewaarborgd, dus het systeem is zowel Partition Tolerant als Consistent.
- Wanneer we ten slotte Consistency opgeven kunnen beide partities zowel in de lucht blijven als updates doorvoeren. In Amsterdam kunnen mensen de key ‘1’ dan een nieuwe waarde ‘D’ geven, en tegelijkertijd in Dublin dezelfde key de waarde ‘E’. Hoewel niet meer consistent, blijft het systeem beschikbaar voor reads én updates, en blijven partities los van elkaar functioneren. Zowel Available als Partition Tolerant dus.
(Dank aan collega Harmen Wessels voor de plaatjes bij dit voorbeeld).
Waarom sommige standaard-voorbeelden van CAP niet standaard-correct zijn
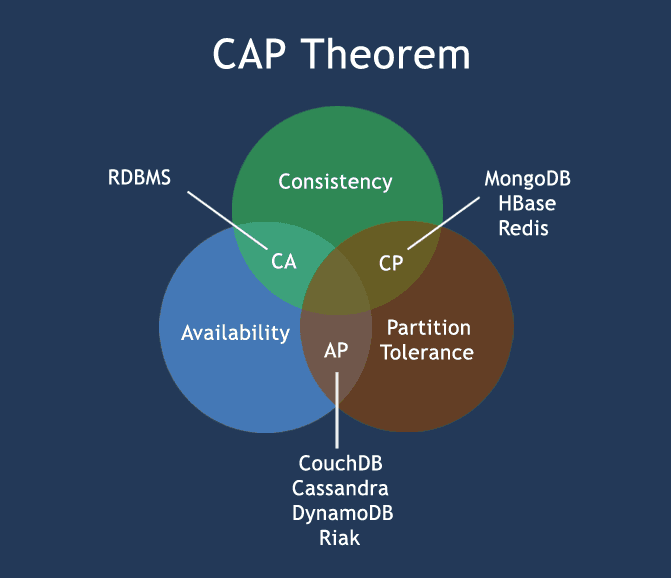
In de praktijk zullen alle systemen een mengeling van belangen en daarbij behorende ontwerpkeuzes hebben. De meeste systemen zijn echter te plaatsen op hun voorkeur voor één van deze drie ‘zijden’:
- Consistency-Availability (en dus minder sterke Partition Tolerance)
- Consistency-Partition Tolerance (en dus minder sterk Availability)
- Availability-Partition Tolerance (en dus minder sterk Consistency)
In het bespreken, evalueren of aanprijzen systemen worden producten, databases en gedistribueerde systemen vaak zonder veel voorwaarden op één van deze zijden geplaatst. Een bekend voorbeeld is, dat een rdbms “altijd” op de CA-zijde zou staan. Of een Big Data-platform meer richting de P.
{kind=link}
{kind=link}
{kind=link}
De realiteit ligt, zoals vaak, veel genuanceerder. Producten als databases en gedistribueerde systemen kunnen vaak op diverse manieren geconfigureerd worden, of afhankelijk van de omstandigheden (kantooruren, belasting van het systeem, aantal actieve gebruikers) andere keuzes met betrekking tot Consistency, Availability of Partition Tolerance.
De volgende twee voorbeelden laten zien dat de standaard voorbeelden niet standaard opgaan:
1. Hadoop en Partition Tolerance
Het Hadoop Distributed File System (HDFS) wordt vaak aangehaald als een systeem dat uitermate ‘Partition Tolerant’ is. HDFS is echter, voorafgaand aan versie 2, een systeem met een Single Point of Failure (SPoF) in de vorm van een NameNode1. Alle lees- en schrijfacties lopen eerst via de NameNode, waar wordt geregistreerd welke bestanden in welke blocks zijn onderverdeeld, en waar deze zich bevinden. De NameNode wijst aan met welke DataNodes er gecommuniceerd kan worden voor bepaalde data. Dit is per definitie niet Partition Tolerant, omdat partities, indien deze optreden, niet los van de NameNode kunnen functioneren. Het is echter ook niet zo dat er géén Partition Tolerance is: gedurende een Map- of Reduce-task is er strikt gezien geen communicatie nodig tussen de NameNode en de DataNodes3.
2. Relationele database (rdbms) en CAP
Relationele databases worden vaak als voorbeeld genomen van de systemen die bij uitstek kiezen voor de ‘Consistency’ en ‘Availability’ ten koste van ‘Partition Tolerance’. De ‘Consistency’ zit ingebakken in o.a. de ACID-eigenschappen die zo belangrijk zijn voor relationele databases. Wanneer relationele databases echter gedistribueerde systemen worden (als ze dat niet zijn, gaat het CAP-theorema ook niet op), zijn er diverse manieren waarop hiermee omgegaan kan worden:
- Log shipping. Bij log shipping draait met de primaire SQL-database een secundaire SQL-database mee, die alle acties op de primaire SQL-database automatisch overneemt. Deze secundaire database is in te stellen als een extra read-only host (bijvoorbeeld voor load balancing van de database reads). Wanneer de verbinding tussen deze twee databases wegvalt, kun je ervoor kiezen om de tweede database read-only te laten draaien. De effecten voor C, A en P zijn hier als volgt:
- het systeem is behoorlijk Partition Tolerant: ondanks de optredende partities blijft het systeem gewoon bestaan, bereikbaar en functionerend.
- Er wordt ingeboet op Availability: Alleen de primaire database kan updates verwerken – de secundaire database niet. Er is echter wel enige vorm van availability: alle partities verwerken reads, en de primaire database verwerkt updates.
- De Consistency is verminderd: wanneer er updates plaatsvinden op de primaire database is er geen consistentie over het gehele systeem, want de secundaire database heeft oudere informatie. Er is echter wel enige mate van consistency, want er is nooit sprake van een conflictsituatie. Bij een herstel van de netwerkverbinding kunnen de updates van de primaire database zondermeer doorvloeien naar de secundaire database
- Merge Replication (SQL Server): Twee databases draaien in dit geval parallel. Wanneer er een netwerkverbinding beschikbaar is, synchroniseren zij de doorgevoerde wijzigingen. Wanneer er geen netwerkverbinding beschikbaar is, blijven beide systemen volledig beschikbaar voor lezen en schrijven. Hier geldt dus een sterke Availability in combinatie met Partition Tolerance, en wordt er ingeboet op Consistency (!)
Waarom een goede voorkennis onmisbaar is bij het plannen van een gedistribueerd systeem
Het CAP-theorema is een theorema dat gaat over gedistribueerde systemen en dat helpt om na te denken over het ontwerp van deze systemen. Het maakt de gevolgen duidelijk van ontwerpkeuzes, en helpt bij het inzicht krijgen in de afwegingen die gemaakt moeten worden bij het ontwerpen van een gedistribueerd systeem.
Het CAP-theorema kan echter niet blind op een bepaalde techniek of een bepaald product geplakt worden: bij het ontwerpen van een gedistribueerd systeem moeten vragen over hoe om te gaan met Consistency, Availability en Partition Tolerance telkens opnieuw gesteld worden, en de uitwerking hiervan hangt in grote mate af van de keuzes die gemaakt worden in het ontwerp. Systemen kunnen dan ook zelden ‘blind’ op één van de ‘zijden’ van de CAP-driehoek geplaatst worden. Met name op het pad naar het maken van een bewuste keuze voor een database-systeem (relationeel, NoSQL of anders) is het belangrijk dat de keuze voor systemen gemaakt wordt op basis van kennis over de diverse systemen, de mogelijkheden op het gebied van configuratie en inrichting, en de consequenties van ontwerpkeuzes – op het nu op het niveau van producten is, of van configuratie en inrichting binnen deze producten.
Wanneer de keuze gemaakt moet worden op welk platform uw gedistribueerde systeem gebouwd moet worden, en welke ontwerpkeuzes hier verstandig zijn, is een goede voorkennis van het speelveld en de mogelijkheden onmisbaar. Bij Info Support hebben we deze kennis in huis, en delen hier graag van uit: toegespitst op uw situatie in maatwerk consultancy, specifiek over een bepaald product / bepaalde stack in één van onze trainingen of in een overzicht van technieken gedurende een lezing of seminar.
1. Er is een Secondary NameNode – deze is er alleen tegen dataverlies indien de Primary NameNode uitvalt en neemt geen functies over.
2. http://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
3. Dit hangt uiteraard af van de configuratie – als een node die een Task uitvoert te lang geen heartbeat gestuurd heeft naar de Job Tracker, wordt de Task namelijk opnieuw gestart.
6 comments
Wat ook belangrijk is om je te realiseren is dat het CAP-theorema uitgaat van een ge-isoleerd system zonder besef van tijd. Dat betekent dat door tijd of ander extern invloed toe te voegen door b.v. een gedistribueerde tijdklok zoals GPS in Google Spanner je voorbij het CAP-theorema kan gaan.
Rolf Huisman
Rolf, hoe zou je met een gedistribueerde tijdklok ‘eromheen’ kunnen gaan? Je blijft toch hetzelfde probleem houden dat bij het optreden van een partitie (= voor een gegeven tijd een niet-bestaan van communicatie tussen twee of meer delen van het systeem) ofwel niet het gehele systeem hetzelfde beeld van de data heeft (Consistency), ofwel niet het gehele systeem beschikbaar is voor alle updates (Availability)?
Koos van Strien
Een gedistribueerde nauwkeurige tijdklok geeft je de mogelijkheid om een beslissing te maken over wat waarheid op een gegeven moment is.
http://research.google.com/archive/spanner.html
http://qconlondon.com/london-2014/presentation/Exploiting%20Loopholes%20in%20CAP
Rolf Huisman
Google Spanner lijkt me in de CP hoek te positioneren.
Tim Mahy
Eigenlijk moet je bij CAP niet alleen kijken wat er gebeurt als er partities optreden, maar ook hoe je zaken weer kunt consolideren tot 1 geheel als de partities weer wegvallen (en de verbinding dus weer terug is). Door het mechanisme wat Rolf noemt maak je het mogelijk om achteraf veel preciezer te reconstrueren wat de volgorde van updates was, waardoor je, ondanks het tijdelijk opgeven van een C, deze toch weer (grotendeels) terug kunt krijgen.
Daarnaast moet je ook rekening houden met tijdsvertraging in verbindingen. Ook al is een gedistribueerd systeem connected, als je geen gebruik maakt van 2PC, dan heb je per definitie ingeboet op C, omdat er ook enige tijd zit tussen een mutatie op het “master” en het “slave” systeem.
Raimond Brookman
Zeer zeker. Dat is m.i. één van de belangrijkste punten om te overwegen wanneer je meer A wilt: uiteindelijk wil je ergens weer een bepaalde mate van C bereiken. Gedistribueerde timers kunnen daarbij helpen om de juiste volgorde de reconstrueren (en dus op het moment dat er geen partities meer zijn weer C te bereiken), maar je blijft inboeten op C.
Een mooie oplossing die heel sterk voor AP gaat is een gedistribueerd versiebeheersysteem als Git. Door de keuze dat iedere deelnemende node een eigen repository heeft, is er nooit maximaal Consistency. Zelfs in een systeem dat zo sterk op AP gericht is, is er echter nog steeds een relatieve consistency binnen één tree wanneer er een push / pull wordt uitgevoerd. Die C kan echter soms pas bereikt worden na het oplossen van ‘Merge Conflicts’. ‘Merge Conflicts’ zijn de ultieme niet-C: twee hosts die elkaar tegenspreken. Deze kun je deels oplossen met behulp van gedistribueerde timers, maar niet helemaal: het feit dat je collega 10 minuten later dan jij een update heeft doorgevoerd in de code betekent niet dat dat de juiste of werkelijke waarde is.
Uiteraard moet je daar rekening mee houden. Dit is echter geen uitzonderingsgeval die buiten CAP omgaat: tijdsvertraging is een optredende partitie. Een master-slave-systeem waarbij de master updates blijft doorvoeren wanneer de slave deze nog niet bevestigd heeft heeft dus ingeboet op C ten behoeve van een klein beetje meer A en P.
Dit raakt ook de kern van de post: in de praktijk zijn systemen niet zomaar te plaatsen op de ‘assen’ CA / AP / CP. C, A en P zijn geen discrete waarden die je zomaar op een product / oplossing kunt plakken: in de praktijk is er altijd sprake van een tradeoff bij de bouw van een systeem, waarbij de verschillende niveaus afgewogen worden (zoals in het master-slave-voorbeeld). Ook blijft het de vraag op welk niveau je deze uitspraken doet: over het hele systeem genomen is HDFS bijvoorbeeld redelijk sterk AC (want partities tussen namenode en datanodes kunnen gewoon niet bestaan), maar ingezoomd op federated namenodes schuift HDFS meer richting CP (federated namenodes verdelen de administratieve last, communiceren niet en werken onafhankelijk van elkaar. Het uitvallen van één van de federated nodes leidt altijd tot verlies van availability). Met name in de gesprekken rond NoSQL / Big Data systemen wordt hier echter nogal eens een rookgordijn gelegd in de vorm van extreme simplificaties (“Ja, maar Hadoop is AP, dus kan geen Consistency garanderen” of “Alle relationele databases zijn AC, dus zijn nooit partition tolerant”) of verkeerde uitleg (met name de P als zijnde ‘horizontale schaalbaarheid’ is een erg hardnekkige).
Koos van Strien