
 0 comments
0 comments Various
Various 
“How many times have you walked up to a SQL Server that has a performance problem and wondered where to start looking?”. Het is de openingszin van een bijzonder leerzame blog post van Paul Randal met de titel Wait statistics, or please tell me where it hurts. Iedereen die wel eens een performance probleem in SQL Server moet onderzoeken, zou hier kunnen, of misschien wel moeten beginnen. Paul geeft in zijn artikel ook een paar goede tips voor degenen die nog dieper willen duiken:
- SQL Server Performance Tuning using Wait Statistics: a beginners guide, een whitepaper geschreven door Jonathan Kehayias en Erin Stellato
- SQL Server: Performance Troubleshooting Using Wait Statistics, een Pluralsight training van Paul Randal.
Erg handig is ook de query die zijn blog post bevat:
WITH [Waits] AS (SELECT [wait_type], [wait_time_ms] / 1000.0 AS [WaitS], ([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS], [signal_wait_time_ms] / 1000.0 AS [SignalS], [waiting_tasks_count] AS [WaitCount], 100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage], ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum] FROM sys.dm_os_wait_stats WHERE [wait_type] NOT IN ( N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR', N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH', N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE', N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE', N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE', N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD', N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE', N'EXECSYNC', N'FSAGENT', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX', N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE', N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE', N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP', N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE', N'PWAIT_ALL_COMPONENTS_INITIALIZED', N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP', N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE', N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH', N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP', N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY', N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP', N'SLEEP_SYSTEMTASK', N'SLEEP_TASK', N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT', N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP', N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS', N'WAITFOR', N'WAITFOR_TASKSHUTDOWN', N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN', N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT') AND [waiting_tasks_count] > 0 ) SELECT MAX ([W1].[wait_type]) AS [WaitType], CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S], CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S], CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S], MAX ([W1].[WaitCount]) AS [WaitCount], CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage], CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S], CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S], CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S] FROM [Waits] AS [W1] INNER JOIN [Waits] AS [W2] ON [W2].[RowNum] <= [W1].[RowNum] GROUP BY [W1].[RowNum] HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold GO
Deze query laat alle waits gegroepeerd zien op soort wait als percentage van alle waits op een omgeving. Op mijn eigen systeem, komt daar het volgende overzicht uit:
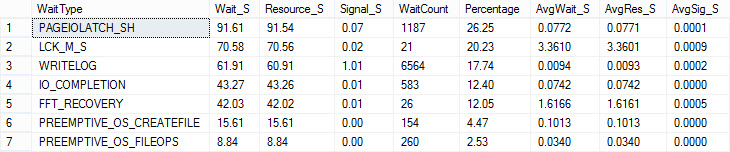
Op basis hiervan zie je dat ik als eerste zou moeten kijken naar de PAGEIOLATCH_SH waits. Paul geeft in de rest van zijn blog post veel informatie over de meest voorkomende waits en mogelijke oplossingen. Nogmaals, een échte ‘must read’!