
 6 comments
6 comments .NET
.NET 
It is time for another blog post! As I was preparing for an xml training, I was just about to read through the xsd specifications when I noticed XML Schema 1.1 became a standard. The W3C calls it a recommendation but basically, it means the same ![]() . It became a standard on April 5, 2012, which means it has been a standard for almost 8 months now! To me, a trainer who also teaches xml related courses, this is big news! There are really a lot of cool new features in xsd 1.1. Because I believe that every developer should know about this cool stuff, I won’t let this go unnoticed and we will look at the new features of xsd 1.1 in this blog post. I will try to summarize all new features in one post, so this could be a lengthy one
. It became a standard on April 5, 2012, which means it has been a standard for almost 8 months now! To me, a trainer who also teaches xml related courses, this is big news! There are really a lot of cool new features in xsd 1.1. Because I believe that every developer should know about this cool stuff, I won’t let this go unnoticed and we will look at the new features of xsd 1.1 in this blog post. I will try to summarize all new features in one post, so this could be a lengthy one ![]() . Let me apologize for the image quality, they become readable when you click on them though.
. Let me apologize for the image quality, they become readable when you click on them though.
The first thing to realize is that xsd 1.1 is completely backwards compatible with xsd 1.0. According to the specs even the xml namespace you should use in your xsd stays the same. So this:

should still work. It is also important to understand that you can’t validate a 1.1 xsd using a 1.0 xsd validator. The 1.0 validator will think you are using wrong/unknown elements in your xsd. Are there any xsd 1.1 validators? You might be asking yourself. I did some research to determine which validators actually implement the 1.1 specs and came to the conclusion that you basically have two choices. You can use Saxon, downloadable from http://www.saxonica.com/. The problem with Saxon is that only the paid version supports xsd validations. Another option, and my preferred choice for now is Xerces-J from Apache, downloadable from http://xerces.apache.org/xerces2-j/. The problem with Xerces is that is only a library, not an executable 1.1 validator. So being a .Net developer I realized I was, well, uhm screwed and I did the unthinkable ![]() … I downloaded and installed Java (which I had to uninstall because of our security policy, Java was insecure
… I downloaded and installed Java (which I had to uninstall because of our security policy, Java was insecure ![]() ) and I built a very small xsd 1.1 validator from source code. I also made a batch file so we can run this normally. This is what I will be using during this blog post and I will provide this as a download at the end of the post.
) and I built a very small xsd 1.1 validator from source code. I also made a batch file so we can run this normally. This is what I will be using during this blog post and I will provide this as a download at the end of the post.
So enough talking, let’s dive into the cool new features! First up are Assertions. Xsd 1.0 was all about checking grammar. We could check if the right attributes were used, we could check if the right datatypes were used and we check if the right values according to our xsd were used. basically we were creating grammar for our xml documents with xsd 1.0. Lets have a look at the following example:
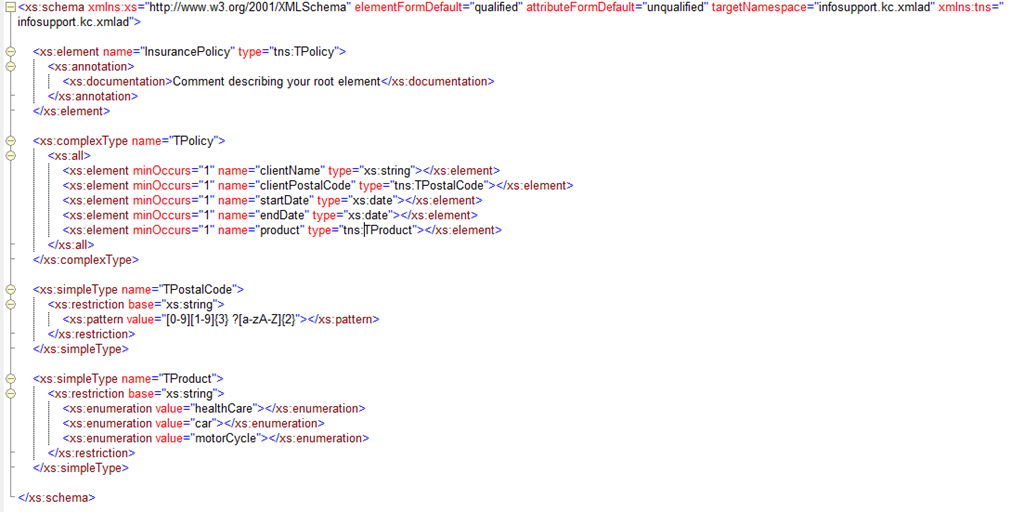
This is a very simple schema which lays down the grammar rules for an insurance policy. The basic rules are simple, a name must be provided, a valid Dutch postal code as well as a valid product (currently we only sell health, car and motor cycle insurances). We could even provide a maximum and a minimum date if we wanted to. This all really cool but soon we will bump our head on the limitations of xsd 1.0. What if want to determine the minimum startDate dynamically? Like “startDate >= current date ”? This can’t be done. Or another simple rule: endDate > startDate. Or something a little more complex: If product == ‘car’ or product == ‘motor cycle’ a license plate must also be provided. The last rule can actually be solved by using the correct sub types in xsd 1.0, but the solution would not be very pretty because the instance document should provide an xsi:type attribute and we are creating a lot of types. We should create a type for restriction, and a type for extension, 2 types extra per product. Also we can’t use an xs:all in our TPolicy because that is not allowed in combination with extension in the base type or the subtype. Adjust this to a sequence would change our xsd functionally so this is not the way to go. Again, simple grammar in xsd 1.0 is ok, real rule based validation does not work.
Enter the new xsd 1.1 assertions. Asserts are really simple, but lean heavily on your xpath 2.0 knowledge. The syntax is simple. Take look at the figure below, which solves the endDate not before startDate issue.
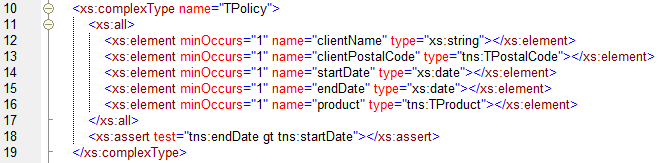
The assert on line 18 does all the magic for us! Pretty cool right? There are a few caveats when using assertions, The first is that the xpath expression in the test attribute should always evaluate to true or false. If you want this to be really clear you can also rewrite the above to:
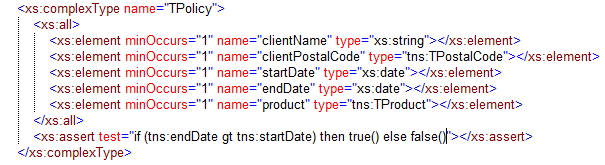
The use of xpath 2.0 makes it a bit more readable. An assertion always goes at the bottom of a complex type definition, So it’s placement should be easy to remember. If I validate the following instance doc:

I will get this error using my parser.

Let’s also solve the license plate problem in case of a car insurance:

You should really take care when you create your assertions. I could have also put this rule in one big assertion and combine them with an ‘and’ but then the error that I get from the parser would not state precisely what went wrong. You should make your assertions very modular. Also notice the way I use the if then else construct of xpath 2.0. It is really usefull right now because of the ‘else’ part. Without it I would also need to specify an ‘or’ with the exact negative condition in it. Also take care that you don’t specify your xpath like this:
if ((tns:product eq ‘car’ or tns:product eq ‘motorCycle’) and tns:license) then true() else
This means again that in the else we need to specify a complete condition, because we won’t know why the else was triggered. It could be because healthCare was insured or because license was empty. The final pitfall when using assertions is the placement of the assertion. You always place it at the bottom of a complex type definition. The element that uses your type definition becomes the root node of your xpath query. In the above example / points to InsurancePolicy element. When you create complex hierarchies you could imagine that multiple types use assertions on the same element, like this:

The asserts will all be checked. In other words, there is no xml file that will succeed validation in combination with this xsd! One of these assertions will always fail.
The xpath in the assert is a little constrained. When you look in the recommendation you will notice that you can use all xpath functions, except the Document function. So no validations that gather data from external xml documents. Also the xpath used in test can’t look up. No parent axis can be used.
We are almost done with assertions, but not quite. There is als a new facet in xsd 1.1 called assertion. Let’s say we want to define a new simple type in our xsd which restricts the xs:integer datatype to values between 0 and 200 and the value can only be an even number. This was impossible in version 1.0 of xsd but now we can express such rules. Take a look at the .xsd below:

Here we see the new assertion facet in action. Take a look at the magical $value variable. This variable holds the runtime value of the element that this assertion is part of. This variable also exists in the xs:assert in complex types, then it holds the runtime content of an element. Can you imagine all the possibilities that we have now with the new assert features? To me this means building business rules engines in xsd! Instead of specifying business rules that a web service should validate in a functional design document we can now specify this in a standard universal way and make it part of it’s WSDL. Endless possibilities..
I really can’t stop about the assertions. One more example ![]() . Suppose we have customers, part of the data that we want to store with the customer is whether we can reach them digitally (email, IM etc) or physical, phone call or a letter. If we can only reach a customer physically we don’t want to see email in our xml. Using assertions and xpath 2.0 we can express this rule very clearly and easily. See below:
. Suppose we have customers, part of the data that we want to store with the customer is whether we can reach them digitally (email, IM etc) or physical, phone call or a letter. If we can only reach a customer physically we don’t want to see email in our xml. Using assertions and xpath 2.0 we can express this rule very clearly and easily. See below:

When validating this instance doc:

This is is the screen that I get:

That’s it for assertions!
The next new feature we are going discuss are ‘Conditional Type Alternatives’. Sound complex right? Basically it is just a way to conditionally assign a type to an element, which is a way to conditionally allow content for an element. Suppose we have a company, with teachers and consultants. Not unlike the one I work for. We want to keep data about our employees. For a consultant we want to keep name, project and customer he works for, for a teacher we want to save name,expertise and courses he can teach. Based on a condition (the function an employee has) we want to use different elements in our xml. We could also achieve this using a complex system of derivations and type substitution or using assertions. When using assertions the xpath would become very lengthy. For conditional content, type alternatives are the way to go. The picture below shows how this works:
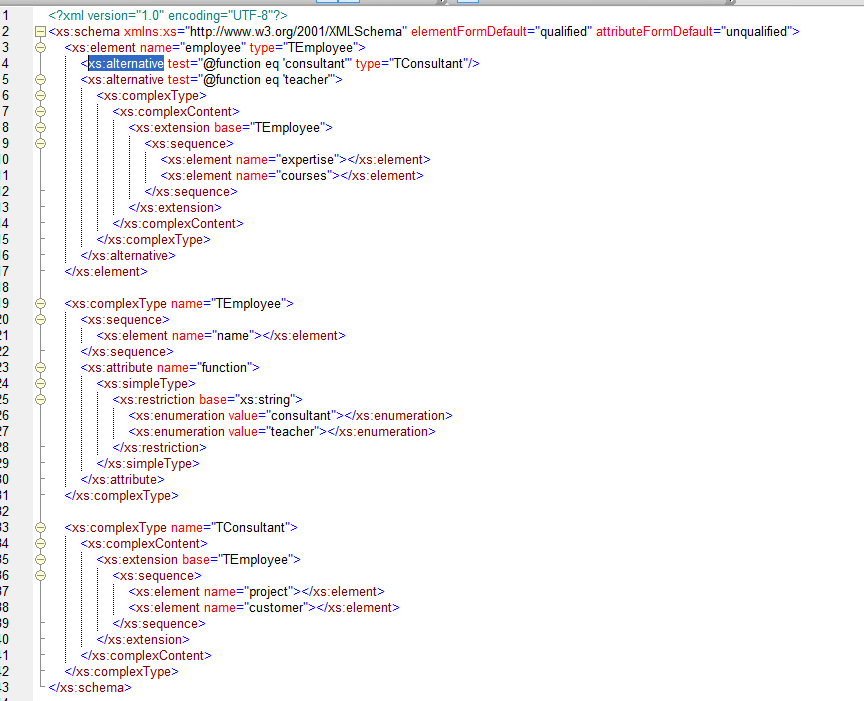
The above figure shows an xsd in which I have an employee element. This element can be of 3 different types. TEmployee if no condition matches. If the function of an employee is consultant the type will be TConsultant, which means we can also save project and customer information. If the function of an employee is teacher the element will be of of an inline defined anonymous type, which means we can save expertise and consultant info. A consultant with courses will not be accepted by this xsd. The Conditional Type Alternatives basically works just like type substitution. Only now the instance doc doesn’t have to provide the type with an xsi:type attribute because the PSVI can be constructed based on the condition defined in the xsd. The alternative types need to be valid subtypes of the type defined on the element on which we use the type alternatives. You can see that in my example I limited the possibilities of the function attribute. You are not obligated to do this. If do not do this but you still want to throw an error if an unexpected value is used you can create a type alternative that matches anything other than the expected values and set the type to xs:error. This is a new datatype that is especially used for reporting errors. Personally I think the above approach is a bit more cleaner and xsd-ish. Suppose our function attribute was defined in an external xsd, and it was defined as a string. In this case we would be obligated to use xs:error to limit our values since we can not adjust the external xsd and restrict the attribute type. You can also use xs:error in combination with xs: override or xs:redefine to redefine global elements and throw errors certain global elements are used. More on that later.
One really big restriction of type alternatives lies in the xpath we can use. In the condition we can only select attributes of the current element, no child or parent elements ![]() . This means that if our function data was defined as a child element, we needed to resort to assertions to get this to work. But otherwise, this feature is pretty cool! Oh and if multiple type alternatives evaluate to true, the first one that evaluates to true is used.
. This means that if our function data was defined as a child element, we needed to resort to assertions to get this to work. But otherwise, this feature is pretty cool! Oh and if multiple type alternatives evaluate to true, the first one that evaluates to true is used.
We are not completely done with type alternatives because the next feature we are going to discuss walks hand in hand with this one. Suppose we have the following xml:

We are all good people here so if the party is on Tuesday we want soda, in the weekend we want alcoholic beverages, preferably cocktails ![]() . We can not use a type alternative for this on the drinks element, because in that type alternative we would need to select the day attribute of it’s parent element. Recall that we can’t access parent elements in the xpath of a type alternative. What would be cool is if we could get that day attribute to inherit to the drinks element so we could use it in the test of a type alternative. With xsd 1.1, we can
. We can not use a type alternative for this on the drinks element, because in that type alternative we would need to select the day attribute of it’s parent element. Recall that we can’t access parent elements in the xpath of a type alternative. What would be cool is if we could get that day attribute to inherit to the drinks element so we could use it in the test of a type alternative. With xsd 1.1, we can ![]() . Take a look at the following schema:
. Take a look at the following schema:

This solves our problem! The trick is the inheritable attribute on the attribute definition of day. A value of true specifies that it should inherit to all descendants. This only works for type alternatives though, we can’t use this with assertions for example. If multiple attributes with the same name inherit, the closest one wins. Also ‘real’ attributes with the same name as inherited ones always take precedence. So inheritable attributes are basically a work around for the xpath restriction of selecting attributes of the current element. What is cool is if you declare inheritable attributes on the document element, they can be used for type alternatives by every element that is in your document. For example a language attribute, that you can use in different places in your xsd to allow translations of certain elements:

You can see here that based on a language attribute, a different format of postal code is expected later on in the document. Because language is defined on the document element, we hook into it’s value anywhere in the xsd! What you can also see here is that we can use type alternatives to work around the unique particle attribution constraint. In xsd 1.0 we would have used a choice to allow for two postalcode formats, only in a choice, two elements can’t have the same name, so we needed to use different names like FrenchPostal and DutchPostal or something. Now we can have two different postal formats but the element keeps the same name ![]() . Last I want to point out the possibilities if you combine type alternatives with assertions, you can use type alternatives to conditionally assign assertions, because assertions are part of a type definition. This allows for incredible flexibility.
. Last I want to point out the possibilities if you combine type alternatives with assertions, you can use type alternatives to conditionally assign assertions, because assertions are part of a type definition. This allows for incredible flexibility.
The following features are called “schema wide attributes”. Not very complex. We could always define attribute groups in an xsd. Now we can specify on the schema element that every complex type should also get these attributes as part of their type definition. Example below

Not very complex, but may come in handy, especially when defining an xsd for something like xhtml, where every element can have class and ID attributes. The scope of default attributes is the xsd file in which they are defined. Imports and includes have no effect. To every complex type in your xsd you can add defaultAttributesApply=false to disable the inheriting of default attributes.
What you can also see from this example is that in xsd 1.1 the xs:all compositor actually became useful! In xsd 1.0 the max occurrence was restricted to 1, what often resulted in sequences of choices to work around this problem. The xs:all can also be used in base types and also in subtypes! But you have to extend an xs:all with an xs:alle, not with a sequence for example. You can also use xs:any in combination with xs:all, also something that couldn’t be done before. When using this, an xsd validator should match known elements according to their declaration and not against the xs:any, that will be used in case of unknown elements. Conclusion: xs:all has become a lot more useful.
Speaking of the xs:any, it and all the other wildcards (anyAttribute etc) also got a few upgrades. Now we can also specify which namespaces we don’t want. In xsd 1.0 we could only specify what we would want. below is an example of the new xs:any in action.

Another new feature that has a lot to do with possible extensions of your instance document is one that is called ‘Open Content’. Suppose we have an xsd that defines the grammar for an xml document that holds information about a book. For now we only keep the title and author as pieces of info. But we know already that this information is going to be extended in the future, may be multiple times with more pieces of information. We could solve this problem by placing xs:any’s through our document. Together with the xs:all we can use now this is a very viable option. But something more flexible has been added to xsd 1.1, something that also works with inheritance and sequences. We can now define the content model of a complex type as open, meaning that the content can be extended, but under the conditions and at places we define. Take a look at the following sample:
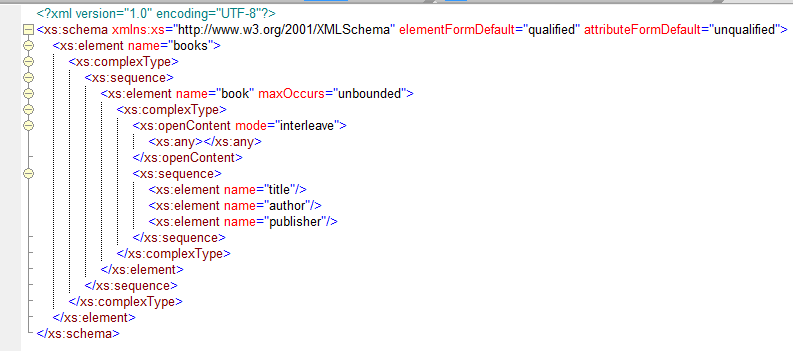
Here I defined the book type as a type with open content. Mode interleave means that we can surround every element that is in book with new content in our instance document and it will still validate. The following xml:
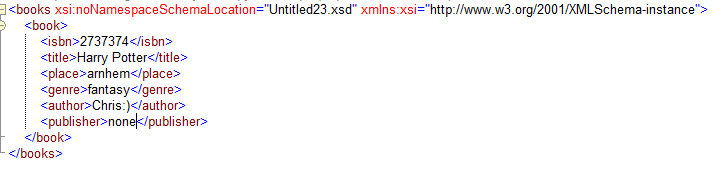
is valid according to our schema, although the isbn, place and genre tags were not defined in our xsd! On the xs:any that lies within the openContent tag the maxOccurs and minOccurs are ignored. They will always be unbounded and zero. We can still use options on the like ##targetNamespace or the new notNamespace options or ##other to signal that the extension elements need to come from another namespace than the target namespace. You can also specify with the processContents attribute if the new elements need to validated, you can choose from lax, skip or strict. The openContent only applies to direct children of book. In other words, if you define a type for author it will not have an open content model and it can’t be extended with unknown elements, unless you also define that type with an open content model. If we change the mode attribute to “suffix”, new elements can only be inserted after the publisher element. So everything after publisher is an extension. There is also a mode called “None”, this meant to be used in combination with inheritance. We will take a look at this now.
Suppose we have two types, The base type has defined open content, the subtype has not. What would be the consequence?

Will TBook have open content? Can we put extension elements around isbn and genre? The answer is simply yes ![]() . The open content model inherits to subtypes! But what if you don’t want the subtype to have any open content? We would need to define openContent with a mode of none in the subtype, this way we can turn off the open content like this:
. The open content model inherits to subtypes! But what if you don’t want the subtype to have any open content? We would need to define openContent with a mode of none in the subtype, this way we can turn off the open content like this:
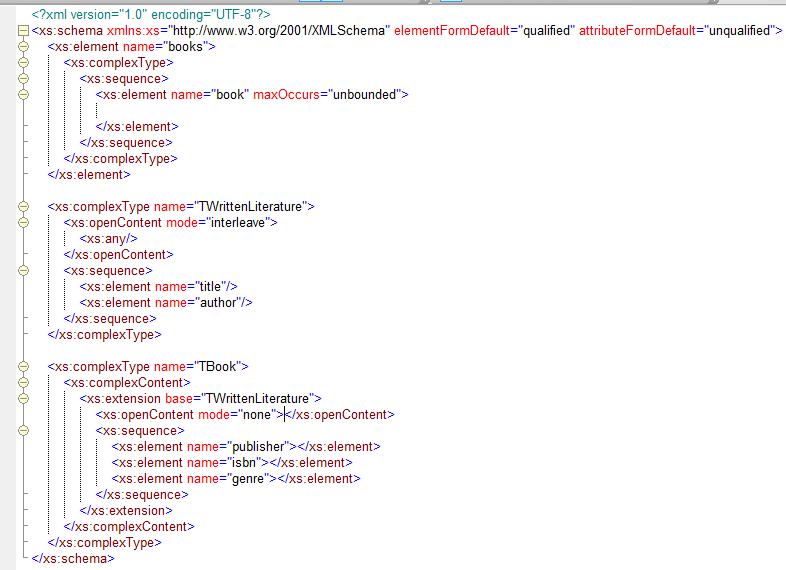
Well actually, the above image is not quite right. Look at that I am doing. I am extending a base type, but I am restricting the openness of it’s content! This does not work! to turn off open content we would need to derive by restriction. There is actually an order in strictness when it comes to the value of the mode attribute. The order from least strict to most strict is
- -interleave
- -suffix
- -none
When you are deriving by extension you can make the subtype more open, if you go from a mode of suffix to interleave for example. So this follows all the basic inheritance rules that were already there in xsd.
Last there is also an xs: DefaultOpenContent tag that you can place at the top of your schema, in this case your whole schema will have open content. It’s behavior is a bit strange. Individual types can still define their own open content, it will take precedence over the schema wide open content. But the schema wide open content takes precedence over inherited open content! Dazzling…![]()
Let’s take a look at working with multiple xsd’s. This is also an area in which improvements have been made. First improvements have to do with inheriting from types from a different target namespace.
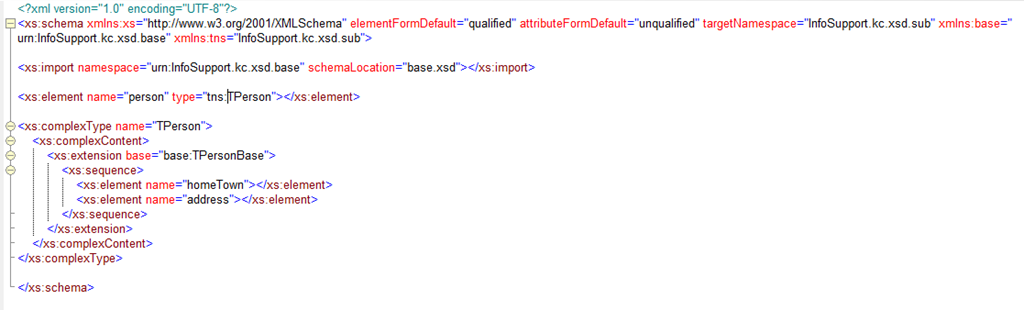
The sample above shows a very simple derivation. I extend a base type from another xsd with a couple of elements. There is no problem here, although it is good to realize that the elements that I am adding belong to the sub namespace and not the base namespace. This becomes a problem when I want to derive by restriction. Because when you are restricting you need to copy the elements to the subtype like this:
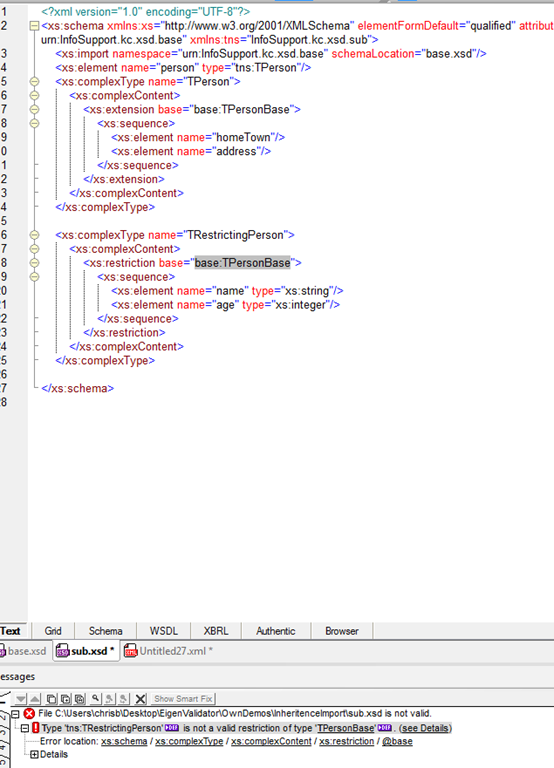
As you can see this will never work! I copied the elements but is not a valid restriction because these elements belong to a different namespace than the originals, and there is no way in xsd 1.0 to specify a different namespace for these elements. That’s why in xsd 1.1 we can do the following:
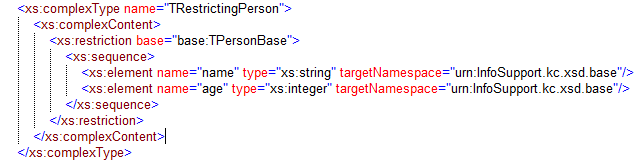
And now it works ![]() . We can use this attribute to specify that these elements should fall in a different targetnamespace than our own. We can only use this attribute in case of restriction and import! Otherwise you will get an error. This is a big improvement, now we can actually make sub types by restriction from types from another namespace. This problem was unsolvable in xsd 1.0.
. We can use this attribute to specify that these elements should fall in a different targetnamespace than our own. We can only use this attribute in case of restriction and import! Otherwise you will get an error. This is a big improvement, now we can actually make sub types by restriction from types from another namespace. This problem was unsolvable in xsd 1.0.
Another change that has to do with different schema is that the xs:redefine instruction has been deprecated. Xs:redefine let us change types from another xsd but with the same targetnamespace by using restriction or extension. The xs: override replaces the redefine and is a lot more powerful, we can completely replace already defined items now, not just restricting or extending, but completely different content models as well.
The next couple of changes I am going to discuss very shortly because they trivial.
- -The substitutiongroup attribute now may contain a list of values, meaning that I can create an element which can replace multiple other global elements. Providing that element is a valid subtype or the same type as those other elements.
- -An explicitTimezone facet has been added for use with the datatypes that support time zones. The values of this facet may be required, prohibited or optional. Before this facet in xsd 1.0 we could require a timezone only by adding a timezone to the value of the min or max facets.
- -A dateTimeStamp has been added/ Just the same as dateTime but a timezone is required.
- -AnyAtomicType has been added as a datatype. It’s valuespace is the union of all the valuespaces of all simple types. Every simple type now inherits from anyAtomic type. The difference with anySimpleType is that the latter can also be a list type, you can not use a list type were anyAtomic is expected.
- -YearMonthDuration and DayTimeDuration have been added. Just as in Xpath 2.0. Done to make durations more comparable.
- -Xsd 1.1 also leaves room for vendors to define their own datatypes and facets. Saxon for example has the
saxon:preprocess facet.
This brings us to last new feature of xsd 1.1. Versioning. We can now create elements and only use them if the schema validator supports a certain version of xsd. To enable this, a new namespace has been added to schema : http://www.w3.org/2007/XMLSchema-versioning. It is very common to use the vc prefix when using attributes from this namespace. These are the attributes you can use.
-minVersion
-maxVersion
-typeAvailable
-typeUnavailable
-facetAvailable
-facetUnavailable
You can use these attributes to specify certain conditions on elements. If such a condition is not fulfilled during preprocessing , your type is removed from the xsd. Since these attributes are in a different namespace they are ignored by older xsd validators. Let’s see some examples.
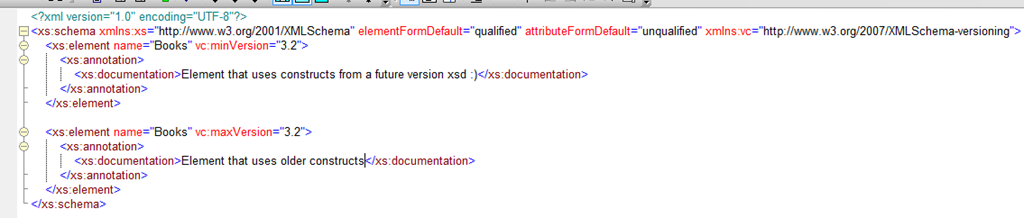
Normally this would throw an error because of duplicates in the same symbol space. But because one of these two is removed during preprocessing of your xsd this won’t throw any errors when validating. MaxVersion is exclusive. Just like the versions, you can also do feature checking with the facet attributes and the type attributes. The typeAvailable and unavailable work with built-in datatypes, not with user defined datatypes. I guess they are also a consequence of the fact that vendors can defines their own facets and datatypes in xsd 1.1
Well, that’s it for the little wrap up on xsd 1.1! Guess it was not really that little…There are a lot of cool features and I can’t wait until more vendors will implement these standards. I really think there are a lot of useful new features implemented in version 1.1, especially the assertions! And a lot of improvements have been made to the already robust validation mechanism that is xsd. There is even more cool stuff on the horizon with the new XSLT 3.0 and Xpath 3.0…
Stay tuned ![]() and happy reading!
and happy reading!
Chris
Demos, examples and the validator
6 comments
Hello,
Fantastic implementation.
Is it possible somehow to spit out the result of the validation into a separate file instead of just the command prompt console?
A couple of options come to mind:
– through a batch file trickery
– by adding a third optional parameter specifying output file name
Thanks a lot,
Yitzhak
Yitzhak
Here is the answer on my own question above.
validate.bat whatever.XML whatever.xsd 2> XSDValidationResult.txt
Yitzhak
Great, thanks!
Chris van Beek
Hi,
WoW Excellent. Thanks a lot for posting this. I never see like this tutorial on the websit.
Purandaran
Hi,
Very elaborate article, good!
A question I have when reading this is, why store business rules in XSD?
XPath is not really a programming language, when things get a little more complicated, you need code. Then that would mean that you have 2 places where you have business rules: 1. XSD / 2. Business Layer
What do you think?
Woutercx
You are right in noticing certain limitations in xpath. But what more do you need? Since xpath 2.0 we have all kinds of expressions (primary, logical, arithmetic etc) to express certain rules. The one thing that I am really missing is the ability to validate against external values.
Do we really need a fully fledged programming language to express business rules? Many business rule engines, have a very limited sub language, to express rules also. You can think of the combination of xsd and xpath as such a language I think.
Why not make xsd, a part of the business layer? Think of a validating webservice for example, that first checks against an xsd, and if there is anything needed that can’t be covered in xsd xpath, performs some additional checks. Because xsd is a well known w3 standard, the xsd could also be understood by information analysts, or even made by information analysts when defining the specs for the service. You could also keep the xsd external, so the business rules can be adjusted without a full compile, deploy step. Perhaps a central location from which the service could download the latest version? For fast changing rules.
But yes this, means, code, and xsd..Different kinds of knowledge, different places to maintain..
Chris van Beek