
 0 comments
0 comments Java
Java 
Functioneel programmeren (FP) is de afgelopen jaren behoorlijk in populariteit toegenomen. Dit is voor een groot deel te danken aan objectgeoriënteerde (OO) talen die functionele aspecten toegevoegd hebben aan de taal. Hierdoor zijn programmeertalen ontstaan die zowel het functionele als het objectgeoriënteerde paradigma ondersteunen. Dit maakt hele krachtige nieuwe programmeerconstructies mogelijk, maar tegelijk combineert het twee paradigma’s die tegenovergesteld zijn in sommige aspecten. Dit brengt interessante kansen en uitdagingen met zich mee.
Dit artikel is geschreven met co-auteur Rinse van Hees en eerder gepubliceerd in Java Magazine #3 2020.
In moderne JVM-talen zoals Java, Scala, en Kotlin komen deze twee werelden, OO en FP, samen. Dit resulteert in hele krachtige patronen die je bijvoorbeeld terugziet in bijvoorbeeld reactive programming. Reactive frameworks gebruiken, veelal, FP constructies zoals higher order functions en lambda’s om de interne staat van objecten aan te passen op basis van events. Maar het combineren van de twee paradigma’s brengt ook valkuilen met zich mee. Doordat de twee paradigma’s vanuit twee hele andere gedachtenwerelden ontsprongen zijn is het op de plek waar ze samenkomen in de code goed opletten. In de rest van dit artikel geven we de achtergrond van de verschillen en willen we laten zien waar de uitdagingen zitten en op welke manier je hier het beste mee om kunt gaan.
Achtergrond
De term object-oriented programming werd geïntroduceerd door Alan Kay in 1966 om naam te geven aan een programma architectuur waar hij toen aan werkte. Hij dacht over objecten als biologische cellen die hun interne state afschermden voor de buitenwereld en alleen konden communiceren via berichten. De state van een object kon alleen worden aangepast via het sturen van berichten. Later zijn ook concepten als inheritance en polymorphism gaan behoren tot het OO-paradigma. Centraal in het programmeren met OO staan class en method, een class is het type object en de method is de methode om er een bericht naar te sturen. Binnen een method wordt er gebruik gemaakt van imperatieve constructies, je geeft de computer instructies hoe hij iets moet uitvoeren. FP vindt zijn oorsprong in de Lambda Calculus. Wiskundige Alonzo Church beschreef in zijn paper “A set of postulates for the foundation of logic” een calculus waarin het gedrag van functies beschreven kan worden. Hij koos hierbij het ?-teken (lambda) om de abstractie van functies uit te drukken. Hieruit is uiteindelijk het FP-paradigma ontsprongen, en refereert de term lambda naar een anonieme functie. Het zal duidelijk zijn dat bij FP de functie een belangrijke rol speelt, aangezien een programma wordt geschreven als de evaluatie en het combineren van functies. Dit is in tegenstelling tot OO, waarin je vaak redeneert vanuit aanpassingen in objecten. In FP zijn functies first class citizen en kunnen ook als parameters van andere functies dienen, zogenaamde higher order functies. Door op deze manier functies te combineren wordt de gewenste functionaliteit gerealiseerd. Een andere belangrijke kracht van FP komt uit het feit dat veel FP-talen pure zijn, wat wil zeggen dat functies geen state kunnen aanpassen en er geen gebruik gemaakt wordt van mutable datastructures. Een voordeel hiervan is bijvoorbeeld dat het evalueren van een functie met dezelfde parameters resulteert altijd in hetzelfde resultaat, dit wordt ook wel referential transparency genoemd. In OO kan de aanroep van een methode een ander resultaat geven afhankelijk van de interne staat van het object.
Probleemomschrijving
De functionele features van een taal zijn vaak handig om bepaalde constructies mee te implementeren, en kunnen goed leesbare code opleveren. Echter is het in veel talen die een combinatie van OO- en FP-paradigma’s ondersteunen vaak lastig om volledig functionele code te schrijven. Hierdoor wordt functionele code met imperatieve code gecombineerd. Hierdoor kunnen een aantal problemen optreden. Bij asynchrone operaties kunnen bijvoorbeeld race condities optreden waardoor de verkeerde waarde aangepast wordt, code in een lambdafunctie met side-effects kan op een ander moment (of vaker) uitgevoerd worden dan de ontwikkelaar bedacht had en referenties naar objecten kunnen onbedoeld vastgehouden worden door een lambda waardoor het geheugen langzaam volloopt.
Het voorbeeld hieronder demonstreert hoe een combinatie van state en het parallel uitvoeren van code tot een onverwachte uitkomst kunnen leiden. Wanneer we sequentieel de lambdafunctie in process uitvoeren zal i telkens een opgehoogd worden en vervolgens opgeteld worden bij het element in de lijst, aangezien de lambdafunctie om de beurt en in de juiste volgorde voor elk element in de lijst uitgevoerd wordt. Omdat onze invoer de getallen 1 t/m 5 zijn verdubbelen we effectief de waarden. Als we hetzelfde parallel doen voeren we de lambdafunctie meermaals tegelijk uit in een onbekende volgorde van de elementen in de lijst. Hierdoor weten we niet in welke volgorde de instructies uit de lambdafunctie uitgevoerd worden. Zo kan het zijn dat we eerst meermaals i verhogen voordat we voor de eerste keer i optellen bij een element uit de lijst. Omdat de lambda niet pure is zie je dat het resultaat niet voorspelbaar is als we een parallelle collectie hebben, en dat is natuurlijk niet de bedoeling.
class Collections {
private var i = 0 // State: i for every Collections instance
// Transforms list elements by executing the lambda function on every element
def process(list: GenIterable[Int]): GenIterable[Int] = list.map { x =>
i += 1 // Increments field by 1
x + i // Result of the lambda: new value is original value plus i
}
}
object ScalaExample {
def main(args: Array[String]): Unit = {
val processSequential = new Collections().process((1 to 5).toList)
val processParallel = new Collections().process((1 to 5).toList.par)
println(processSequential.mkString(", "))
// Output: 2, 4, 6, 8, 10
println(processParallel.mkString(", "))
// Output: 3, 5, 4, 8, 9
}
}
In de praktijk zien we vooral fouten optreden wanneer niet-pure functies gebruikt worden in functionele code. Voorbeelden hiervan zijn een lambdafunctie die een setter aanroept, methoden op een builder gebruikt of een geobserveerde waarde opslaat in een field. Ook zien we fouten bij asynchrone operaties, bijvoorbeeld bij reactive programming. Bij reactive programming beschrijf je de operaties die je uit wilt voeren waarbij het framework kan bepalen hoe het uitgevoerd kan worden op bepaalde invoer. Hierdoor hoef je als developer niet zelf taken op verschillende threads uit te voeren, maar dat neemt niet weg dat code op verschillende threads uitgevoerd kán worden. Dit levert soms situaties op waarbij niet voldoende nagedacht wordt over welke thread precies wanneer welke waarde leest of schrijft. In het onderstaande voorbeeld zie je een patroon dat vaker voorkomt wanneer reactive programming gecombineerd wordt met bijvoorbeeld web frameworks of Android. De events worden parallel en asynchroon afgehandeld op verschillende threads. In het voorbeeld hieronder ontstaat hierdoor een bug omdat er state geüpdate wordt op hetzelfde object in alle threads. Daarnaast ontstaat er een object leak omdat er referenties vast worden gehouden bij het aanmaken van nieuwe subscribers. Dit laatste kan voorkomen worden door de benodigde gegevens uit het object naar lokale variabelen buiten de scope van de lambda toe te kennen en deze lokale variabelen in de lambda te gebruiken. Dit voorkomt dat er een object reference vast gehouden wordt in de lambda.
import io.reactivex.rxjava3.core.*;
import io.reactivex.rxjava3.schedulers.*;
class Main {
public static void main(String[] args) throws InterruptedException {
SomeObject someObject = new SomeObject();
Observable vals = Observable.range(1,1000);
Observable otherSource = Observable.range(1,10);
vals.flatMap(val -> Observable.just(val)
// Schedule handling of subscribers on different threads, this is usually done by, for example, a web or android framework
.subscribeOn(Schedulers.io())
// The next lambda refers to an object that will be shared across the different threads
// The addition operation is not atomic therefore the correct result is not guaranteed
.map(i -> {someObject.someValue += 1; return someObject.someValue;}))
.subscribe(val -> someObject.handle(otherSource));
System.out.println(someObject.someValue);
// Expected output: 1000
// Actual output: anywhere between 920 and 1000
}
private static class SomeObject {
int someValue = 0;
void handle(Observable source) {
SomeObject someObject = new SomeObject();
// The next lambda has an object reference to _this_ which means that for as long as the subscription lives this object cannot be garbage collected
// The same is true for someObject
source.subscribe(n -> someObject.someValue += this.someValue);
}
}
}
Detectie door tools
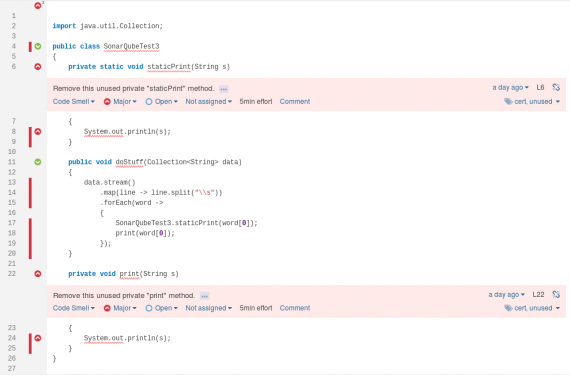
Geen enkele developer schrijft alleen maar perfecte code. Daarom worden tools zoals SonarQube en SpotBugs gebruikt om te helpen om (mogelijkheden tot) bugs zo snel mogelijk te vinden. Echter, deze tools zijn nog niet altijd in staat om goed om te gaan met de combinatie van de OO en FP paradigma’s. De tools zijn gebaseerd op historisch onderzoek naar de relatie tussen code constructies en eerder gevonden bugs, de zogenaamde code smells. Dit type onderzoek is gedaan voor OO en FP los van elkaar. Gezien de combinatie van de twee pas relatief recent een vlucht heeft genomen zie je dat er nog weinig onderzoek is gedaan naar het ontstaan van bugs in het snijvlak van OO en FP. De genoemde tools gebruiken om die reden de regels die voornamelijk óf voor OO danwel voor FP zijn. Hierdoor glippen helaas relatief veel typische multi-paradigma (potentiële) bugs door het net van onze continuous integration pipelines. Hiernaast zien we ook het tegenovergestelde, waar tools bepaalde constructies afkeuren terwijl het valide code is. Het voorbeeld in de afbeelding hieronder werd voor het eerst gemeld in 2016 en pas eind 2019 opgelost in SonarQube 6.0 (SONARJAVA-2084).
Oplossingen
De genoemde problemen kunnen worden voorkomen door goede afspraken te maken over wat je in een functionele context mag doen. Helaas is dit op dit moment iets dat je als ontwikkelaar vooral zelf in de gaten moet houden. Zo kun je immutable datastructuren gaan gebruiken in plaats van objecten met getters én setters. Ook het reduceren van het aantal componenten in je applicatie met state zal het aantal plekken waar die state onbedoeld aangepast kan worden naar beneden brengen.
In Java moet je zelf final voor een variabele zetten om deze niet hertoewijsbaar te maken. Veel developers doen dit echter niet consequent, waardoor er variabelen aangepast kunnen worden terwijl dat niet noodzakelijk is. In Kotlin en Scala moet je altijd expliciet de keuze maken door val (equivalent aan final) of var (hertoewijsbaar) te gebruiken. Hierdoor komt het veel minder voor dat een waarde per ongeluk aangepast kan worden.
Java staat niet toe om een object aan een lokale variabele toe te wijzen vanuit een lambdafunctie omdat dit voor concurrencyproblemen zou zorgen. Door deze beperking helpt de compiler je om het onbedoeld aanpassen van een referentie tegen te gaan. In Kotlin en Scala mag het toewijzen van een nieuwe waarde aan een lokale (mutable) variabele echter wel, doordat de compilers van deze talen de restrictie niet hebben. In Java kun je wel aanpassingen maken aan objecten waar je een referentie naar hebt. Wanneer je probeert om een lokale variabele vanuit een lambda aan te passen stelt IntelliJ voor om een AtomicReference te gebruiken. Je past dan de referentie in de AtomicReference aan, en niet de referentie van de variabele. De concurrencyproblemen zijn hiermee wel opgelost, maar dit helpt niet bij het voorkomen van onbedoelde wijzigingen. Zie het voorbeeld hieronder.
public class IdeaExample {
public void effectivelyFinal() {
String local = null;
final Runnable r = () -> {
local = "Bar";
};
}
}
public class IdeaExample {
public void effectivelyFinal() {
// Applied suggested solution in IntelliJ
AtomicReference local = new AtomicReference();
final Runnable r = () -> {
local.set("Bar");
};
}
}
Arrow is een Kotlin library die veel functionele concepten toevoegt of uitbreid. Arrow heeft een mechanisme om het aanroepen van niet-pure functies vanuit een pure functie op compilerniveau te voorkomen. Mocht je functioneel programmeren in Kotlin is dit een handige feature, echter, dit werkt alleen wanneer je code ontworpen is om dit te ondersteunen. Als developer moet je dit dus consequent in je eigen methoden en functies inbouwen om hiervan gebruik te maken.
Voor immutable datastructuren zijn diverse hulpmiddelen beschikbaar. In Kotlin en Scala is dit relatief makkelijk met respectievelijk data classes en case classes, al heb je hier nog wel de optie om bepaalde properties mutable te maken. Voor Java zou je de Immutables library kunnen gebruiken. Deze library heeft een annotation processor om immutable datastructuren op basis van een interface te genereren.
Onderzoek
In ons dagelijkse werk zien we dat de populariteit van combinaties van OO en FP alleen maar toeneemt. Hierom doet Info Support Research onderzoek naar de mogelijke fouten die hierbij op kunnen treden en methodieken om deze problemen te detecteren. In 2017 zijn we begonnen met het onderzoek naar codekwaliteit van multi-paradigma constructies in Scala. Hieruit bleek dat het combineren van metrieken voor OO en FP constructies (al dan niet in licht aangepaste vorm) goed werkt om foutgevoelige code te vinden. In 2019 vonden we een correlatie tussen het gebruik van dit soort constructies en foutgevoeligheid in C#. Op dit moment onderzoeken we of deze relatie ook bij Scala te vinden is en hoe we de detectie van de oorzaken kunnen verbeteren. We hopen de resultaten hiervan in een volgend artikel met jullie te kunnen delen.
Conclusie
De combinatie van objectgeoriënteerde en functionele programmeerparadigma’s is bijzonder krachtig maar niet zonder risico. Tools als SonarQube en Spotbugs kunnen typische problemen hierbij op dit moment onvoldoende detecteren. Met ons onderzoek hopen we manieren te vinden om deze problemen en code smells beter te detecteren.
We hopen dat we wat meer inzicht hebben kunnen geven in de uitdagingen van het combineren van OO en FP op de JVM en de uitdagingen die daarbij nog te overwinnen zijn. Voor ons onderzoek zijn we altijd op zoek naar interessante voorbeelden en ideeën. Het onderzoek waaraan we refereerden kun je bekijken op de Info Support research website en daar vind je ook onze contactgegevens.