
 0 comments
0 comments .NET
.NET 
*Moved to: http://fluentbytes.com/how-to-improve-your-code-reviews/
As you might know I spend my time, not only presenting at conferences and writing articles, but I am also product owner for our ‘endeavour software factory’ (a consistent set of practices, guidelines and building blocks that we use to build software to high quality standards in the smallest amount of time possible) and architect on large projects we run in our company.
In that role, I do code review work and I did an interview with fellow ALM MVP’s at the MVP summit last march. Adam Cogan (Microsoft Regional director and ALM MVP) and Terje Sandstrom (aka TJ and also a ALM MVP)
We did an interview with him on how we look at a codebase and how we go about conducting the review. It was interesting to see how similar we approach a codebase, that we had never seen and what feedback we would give on that codebase.
The interview with me and Terje is now available online at SSW.TV (http://tv.ssw.com/1709/important-tips-for-improving-your-architecture-and-code-reviews-with-marcel-de-vries-and-terje-sandstrom)
So if you don’t have the time to watch the video in full, here is a small recap of the steps we normally take and what are the things that we think are important for a good codebase:
Ensure that the codebase compiles on a fresh PC
How stupid it may sound, the number of times I came across a codebase that I could not compile is just crazy. I always want to do a sanity check first and see if I get the solution from version control, if I am able to compile it. That also is required if you want to use any of the analysis tools, that I am used to use for a code review. If your codebase requires a specific setup on the local machine, make sure you include that documentation as part of your solution, so your colleague does not have to search for it. I personally like a brief text document that describes the steps of setting thins up. SSW also has some rules that you might find helpful(http://rules.ssw.com.au/SoftwareDevelopment/RulesToBetterDotNETProjects/Pages/DoYouMakeInstructions.aspx)
Of course the best would be to don’t have any dependencies outside of the solution. Use tools like NUGet to get the dependencies with 3th party products instead of requiring an install on the local machine.
Have a look at the project/solution structure and see if it aligns with the overall architectural design
To get a good understanding of a codebase, have a look at the solution structure at first. How many projects are in the solution. Is there a logical structure that shows e.g. the layering that is applied to the codebase. Did they did a good job of segregating the Unit Test project from the actual implementation. In our company we have a strict set of guidelines on how you create a good solution structure. We always work from a technical solution architecture. In that architecture document (Enterprise Architect preferred, if not a PowerPoint, Word document will do) you at least will find the system and subsystem breakup of the entire solution you want to build. We always want to have a good traceability between the envisioned architecture and the way the codebase is created. So I always look at the architectural breakup that is envisioned and the way that is reflected in the solution structure. If there is no relationship between the two, then this is the first talking point with your developers to figure out why that is the case. Did the architect do a poor job in creating good distinct blocks of functionality or did this happen because the developers did not pay attention to how the solution was envisioned and just came op with a solution structure that more or less evolved instead of being engineered?
So with that, that is why I disagree with http://rules.ssw.com.au/SoftwareDevelopment/RulestobetterArchitectureandCodeReview/Pages/DoYouReviewTheDocumentation.aspx in that I first of all don’t think that using UML has to do anything with old school thinking or programming. I believe it is crucial to engineer a solution, before you start coding. Especially when you work on projects where you know the codebase will become huge, it is crucial to get the modules, subsystems and the configuration items specified before you start building the solution. Starting with code without any proper engineering is in my opinion cowboy behavior and will get you into big refactoring efforts later on in the project. Be careful here, I am not saying you need big design upfront! All I am saying here is that you need to think before you code! Using engineering tools and a well understood notation as UML can help a lot in structuring requirements and sketching the solution domain.
Use a tool like the visual studio dependency graph analyzer to look at the dependencies of all assemblies and see if there are any architectural smells
To get a good feel on how a code base works, a great starting point is doing a dependency analysis of the solution you are looking at. With Visual Studio 2010 or 2012 you have the Dependency Graph and other tools as part of the architecture tools in the Ultimate version. The most important part you can learn from those diagrams is if there are any strange violations of dependencies that you did not expect to be there. During our interview, Adam gave us a code base we had never seen before.
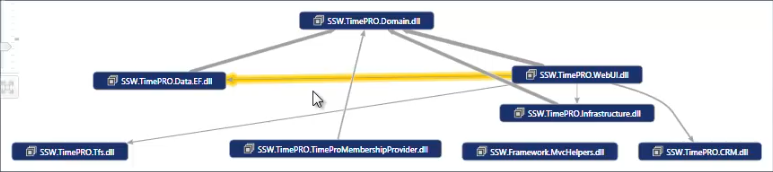
Figure: During our interview we picked up some interesting information by the fact that we found direct relationships between the web UI views and the Entity object model (the yellow line). Based on their solution structure, they should not have such a dependency so it was a thing we could dive into and see why that was the case.
Always be careful not to pre-judge right away that a code base is not good, because of such a dependency! Take the opportunity to dive deeper on the why, since there might be a good explanation for this.
e.g. using the generated entities as Data Transfer Objects (DTO) between your layers, which is a pattern that is pretty common.
Look at the code analysis warnings that are suppressed in the codebase, for particular rules of interest
Code Analysis can also be a good source to find problems in the codebase. Check first if Code Analysis rules is turned on and secondly see which rule set they use. In Visual Studio 2010 and 2012 you have the notion of Code Analysis profiles and I have a specific set that I care about. They should have at least the “Microsoft Recommended Minimum Rules” on. This set will not generate tons of warnings for your solution and there are some really important ones in there, especially on security.

Figure: Check what rule sets are set. They should have at least the “Microsoft Recommended Minimum Rules” on.
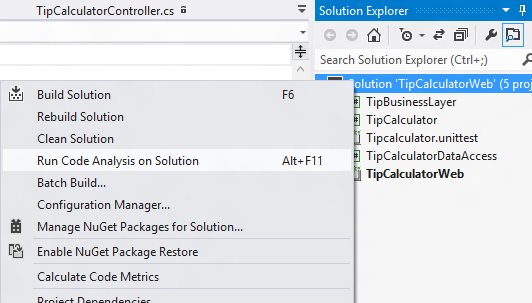
Figure: Run code analysis on the solution and see if there are any violations
Look at the code base with an analysis tool like Code Metrics calculator build into Visual Studio or a tool like NDepend
In Visual Studio 2008, 2010 and 2012, we got a great feature called Code Metrics. (built by Cameron Skinners team). What this does is inspect your code at the IL level (.net binary format) and look at the following aspects of your code base:
- Cyclomatic complexity
- Depth of inheritance
Class coupling
#lines of code -
Maintainability index (calculated based on the the previous metrics)
-
Terje has a great blog post where he explains what the levels of these metrics should read and when you can suspect things are might be wrong. (http://geekswithblogs.net/terje/archive/2008/11/25/code-metrics—suggestions-for-appropriate-limits.aspx) Basically you want to keep the Cyclomatic Complexity below 10, and Class coupling below 20.Looking at these numbers can help find bad coding patterns in the code base.
-
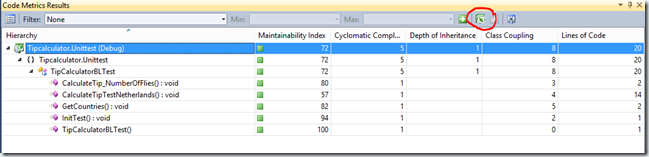
-
Figure: Export to Excel because filtering does not work independently of the hierarchy
-
For easy access you can export the results from Visual Studio to Excel (see how we did this in the interview) and from there, we dive in deeper where the problems might be lurking.
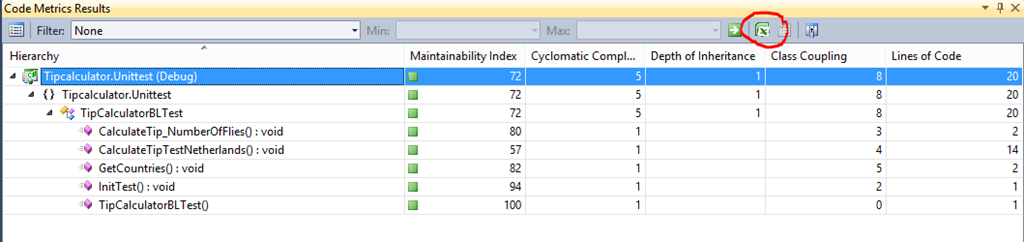
Look at specific code patterns
One good example here is the overuse of For loops, while they could have been expressed using LINQ
Take the following example:
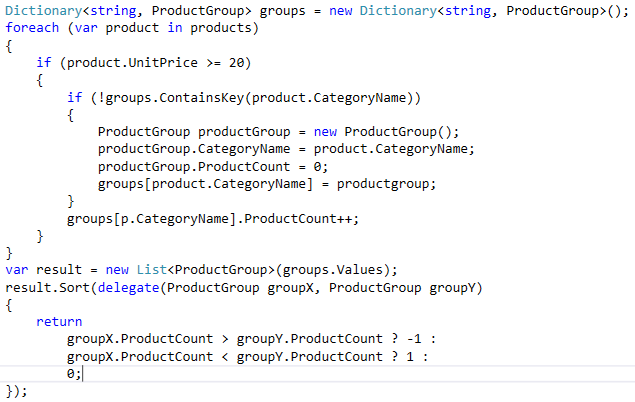
This code really screams to be rewritten in just a few statements. Your goal should be to express what you want in stead of writing how you get to that result and LINQ is the perfect answer for that. You should rewrite this as follows:

Look at how much this improves the readability of your code! One thing that I would like to call out here is the use of the variable names in the lambda expressions. I see ton’s of developers write them with only one letter variable names. I think this is a bad practice and I will explain to you why:When you read the code you should be able to read it like a piece of text and it should explain what it does. When I would have used the variable name n instead of product here, that is just confusing. Especially for people who have a hard time in understanding Lambda and LINQ expressions. I get a lot of pushback on this from the more “Einstein” developers, because they believe that if people could not read that syntax, they should not touch the code. I prefer to turn that around and say: make sure any novice programmer can understand your code and you are the best programmer in my book! Simply because your code is maintainable by all types of developers and it will keep my maintenance cost for the codebase lower. complex code constructs and poor named variable names will increase the maintenance cost, period!
Simple rule of thumb for naming your variable in LINQ and Lambda expressions:
If a variable represents a single word, you use that word describing the variable. If the variable is a composition of words, you are allowed to abbreviate it by using the first letter of each word.
Look at some anti patterns
A good example here is the overuse of Dependency Injection frameworks.
In general it is a good practice to use interfaces in your code so you can swap the implementation in and out when needed. this is especially good for testability of your application and the ability to use Mocks or Stubs when running your unite test. While this is a good practice, this does not mean you need to use a Dependency Injection framework everywhere. Depending on the framework you use, your code becomes very hard to grasp from a flow perspective. Looking at the code and reading through becomes more complex. Where did an instance come from? it depends on the framework you used.
Only use a dependency Injection Framework when you really need it! and when do you need it, well when you need a pluggable architecture. If your requirements don’t explicitly state that the application needs to have the ability to plug in new stuff without recompiling the whole solution and based on configuration, then it makes sense.
Rule of thumb here is that it is better to keep it as simple as possible! Only add complexity when you need additional flexibility.
Look at comments
One final thing that I would like to emphasize, that really helps the maintainability of your code, is comments. Developers tend to forget to write down the thought processes they went through before they decided on a certain coding pattern.
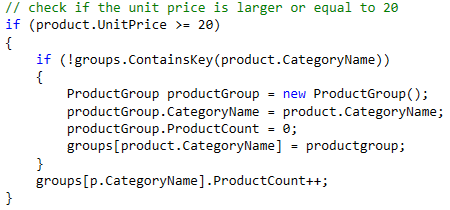
Figure:Useless comments that should be removed since it only adds clutter to the code!
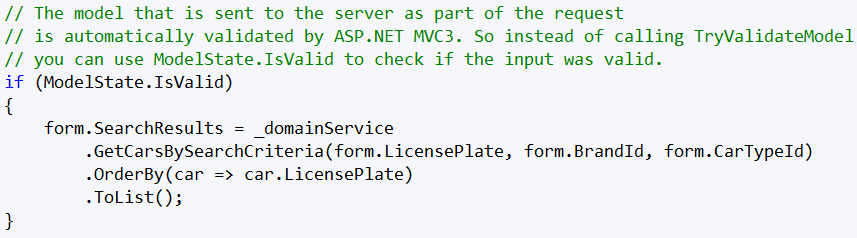
Figure: Great comment why a specific type of validation is chosen over an other used pattern
My common rule for comments is: Add comments when you use coding patterns that deviate from the regular path. No comment, means you did not think it through thoroughly and I will flag the code as: “needs explanation!”.
The code should explain itself when reading
As I say in the interview, we like to keep the rule that your code should ‘read like poetry’ and if that is the case, you can ensure everyone understands what you are doing.
Enjoy the interview and and if you have some great tips of your own for better code reviews, please leave a comment.
b.t.w. Terje also posted some additional information about the interview that is an interesting read: http://geekswithblogs.net/terje/archive/2012/06/24/video-on-architecture-and-code-quality-using-visual-studio-2012ndashinterview.aspx
Special thanks to the team at SSW for their hard work on getting the interview online!
Follow my new blog on http://fluentbytes.com