
 1 comments
1 comments Various
Various 
Application logging. Have you ever had to choose between detailled logging or performance? Where you on one side wanted to log something on a certain level of detail while you knew that this would have an enormous impact on the performance of your application? This is exactly the situation I was in while working on some high-load services at Twyp.
Always the dilemma, should I log this on DEBUG or INFO?

When you are working on your application you have to take into account that this code is going to be running somewhere soon. Someone (preferably you yourself) will be maintaining this code. If you have ever had to analyse some incident and you found that the logs were not of use at all, you will know the pain.
Luckily there are some people that wrote tips on how you can write proper log statements. But keep in mind that the only thing that counts, is the value of the logs to the person or system reading them. If you ever maintained a production application you will know what I am talking about. Applications are logging errors and warnings but you simply don’t understand what exactly caused this error as you are missing vital parts of the context. So, the answer would be to simply enable debug logging, right? Unfortunately it isn’t that simple.
Enabling debug logging has two major drawbacks
- Debug logging usually contains more sensitive information about operations. You simply don’t want to be logging that someone specific is making a transaction with some sensitive description… (I leave those up for your imagination)
- Developers tend to write a lot of debug statements. Imagine 12 debug statements per service request times 100,000 requests / min. Within the hour you’ll have 72 million log statements.
And aside from these issues, you should also ask yourself, is all this information useful? 99% of the time you will not need this kind of detail, especially in the cases where everything is running just fine.
At Twyp we were struggling with this dilemma. Initially we decided to optimise debug logging in the code and then turn it on on production. This was a huge help to our operations people as they finally had all the information about a problem that they needed. But we also noticed that our services started to slow down more and more.
Before you read on, I need to warn you that this blog post is about applicative logging. You should never optimise audit- or security logging to the point that you may lose data!
Logging using the contextual-logbuffer
So we need to find a way to achieve the following goal:
Only log relevant log statements that can help to resolve problems.
This is exactly what the contextual-logbuffer provides. You could best describe the contextual-logbuffer in the following way:
A contextual logbuffer is an interceptor running in your log framework that buffers parts of your logs and only flushes this buffer when there is an event that requires previous or future logging to be flushed to disk.
The contextual logbuffer works based on a FIFO buffer. It stores all log messages within a certain range (e.g. DEBUG up until INFO). Only whenever a configurable threshold is reached will the buffer flushed to disk. This threshold normally is any log message of a certain log level, usually this would be WARN. This means that all DEBUG and INFO log messages are buffered until a WARN or higher is triggered. If your application is never generating warnings or errors then your application will not log anything anymore, as the buffer is never flushed.
A picture says more than 1,000 words, so to put this into perspective check out the diagram below.
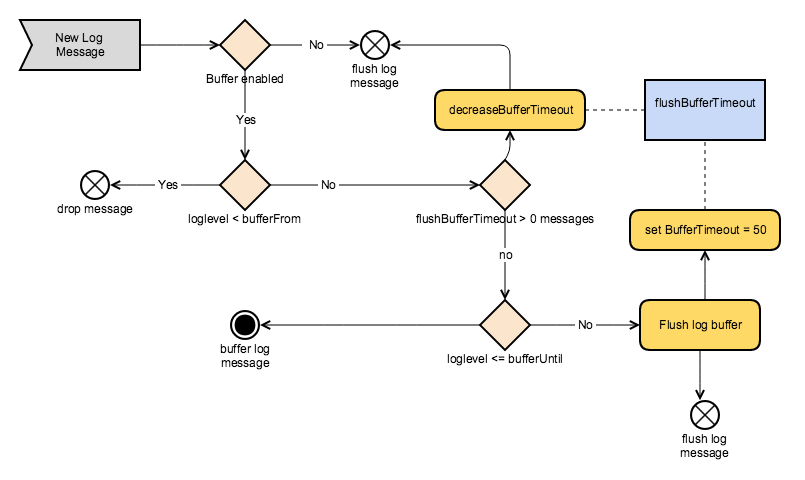
This mechanism provides a way to always have logging available on the level you need while it prevents the performance hit of logging all log messages. There is one drawback to note though. Sometimes it can be very useful to have logging available in cases where there was no fault in the system. A typical example could be a customer complaining about a certain issue. If there was no warning or error for that specific scenario, you will not find any logs to help you with the customer complaint. In this case I would recommend you to fall back on your audit logs, which at least should be able to provide you with some evidence.
 I have built a reference implementation of this system using Logback. A closely related implementation is currently being used in production for some of my projects.
I have built a reference implementation of this system using Logback. A closely related implementation is currently being used in production for some of my projects. ![]()
How do others handle this problem?
Every major project at a certain point will face this issue. Especially products like Facebook, Netflix and Ebay will have an enormous amount of logs. To be honest, I can’t even imagine how these guys manage this.
Google however published a paper on this subject. I am mentioning this specifically because Google has a whole different approach. I recommend to spend some time to read the great summary of Adrian Colyer. Paper: Dapper, A Large Scale Distributed Systems Tracing Infrastructure.
One comment
Nice! In a performance tuning workshop Kirk Pepperdine recommended a logging framework with minimal overhead: https://github.com/OpenHFT/Chronicle-Logger
Frank de Groot - Schouten